A subscription
is essentially a formal request and registration of that request for
data that is being published. By definition, you subscribe to all
articles of a publication.
When a subscription is being
set up, you have the option of either having the data “pushed” to the
subscriber server or “pulling” the data to the subscription server when
it is needed. This is referred to as either a push subscription or pull subscription.
As shown in Figure 1,
a pull subscription is set up and managed by the subscription server.
The biggest advantage here is that pull subscriptions allow the system
administrators of the subscription servers to choose what publications
they will receive and when they receive them. With pull subscriptions,
publishing and subscribing are separate acts and are not necessarily
performed by the same user. In general, pull subscriptions are best when
the publication does not require high security or if subscribing is
done intermittently when the subscriber’s data needs to be periodically
brought up to date.
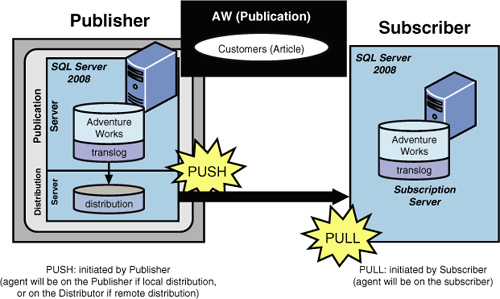
As you can also see in Figure 19.17,
a push subscription is created and managed by the publication and
distribution server. In effect, the distribution server and all the
agents that do the work are pushing the publication to the subscription
server. The advantage of using push subscriptions is that all the
administration takes place in a central location (on the
publication/distribution server side). In addition, publishing and
subscribing happen at the same time, and many subscribers can be set up
at once. This type of subscription is also recommended when dealing with
heterogeneous subscribers because of the lack of pull capability on the
subscription server side.
Anonymous Subscriptions (Pull Subscriptions)
It is possible
to have “anonymous” subscriptions. An anonymous subscription is a
special type of pull subscription that can be used in the following
circumstances:
When you are publishing data to the Internet
When you have a huge number of subscribers
When you don’t want the overhead of maintaining extra information at the publisher or distributor
When all the rules of your pull subscriptions apply to all your anonymous subscribers
Normally, information
about all the subscribers, including performance data, is stored on the
distribution server. Therefore, if you have a large number of
subscribers or you do not want to track detailed information about the
subscribers, you might want to allow anonymous subscriptions to a
publication. Then little is kept at the distribution server, but it then
becomes the responsibility of the subscriber to initiate the
subscription and to keep synchronized.
The Distribution Database
The
distribution database is a special type of database installed on the
distribution server. This database, which is as a store-and-forward
database, holds all transactions waiting to be distributed to any
subscribers. This database receives transactions from any published
databases that have designated it as their distributor. The transactions
are held here until they are sent to the subscribers successfully.
After a period of time, these transactions are purged from the
distribution database. In some special situations, the transactions
might not be purged for a longer period, enabling anonymous subscribers
ample time to synchronize. The distribution database is the heart of the
data replication facility. As you can see in Figure 2, the distribution database has several MS tables, such as MSarticles.
These tables contain all the necessary information for the distribution
server to fulfill the distribution role. Following are some of these
tables:
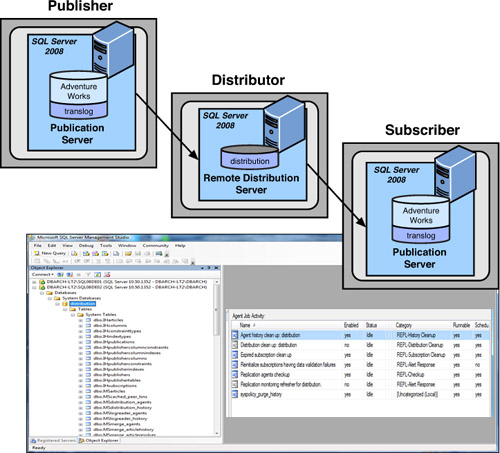
All the different publishers who will use this distribution server— Stored in the MSpublisher_databases and MSpublication_access tables.
The publications and articles that will be distributed— Stored in the MSpublications and MSarticles tables.
The complete information for all the distribution agents to perform their tasks— Stored in the MSdistribution_agents table.
The complete information of the executions of these agents— Stored in the MSdistribution_history table.
The subscribers— Stored in MSsubscriber_info, MSsubscriptions, and other related tables.
Any errors that occur during replication and synchronization states— Stored in MSrepl_errors, MSsync_state, and related tables.
The actual commands and transactions that are to be replicated— Stored in the MSrepl_commands and MSrepl_transactions tables.
Heterogeneous (non-SQL Server) publishers’ or subscribers’ information— Kept in the tables whose names begin with IH, such as IHpublishers, that will contain one row for each non-SQL Server publisher for which this distribution server distributes information.